
Why GPT‑5‑class models matter for creating better Agentic Systems?
evolving from autocomplete to decision engines


From autocomplete to decision engines: Why GPT‑5‑class models matter
We don’t need another model that sounds smart. We need one that can hold complex goals in its head, make plans, change course when the world pushes back, and finish the job. That’s the leap with GPT‑5‑class systems: moving from eloquent assistants to dependable decision engines that execute through ambiguity.
What’s fundamentally different?
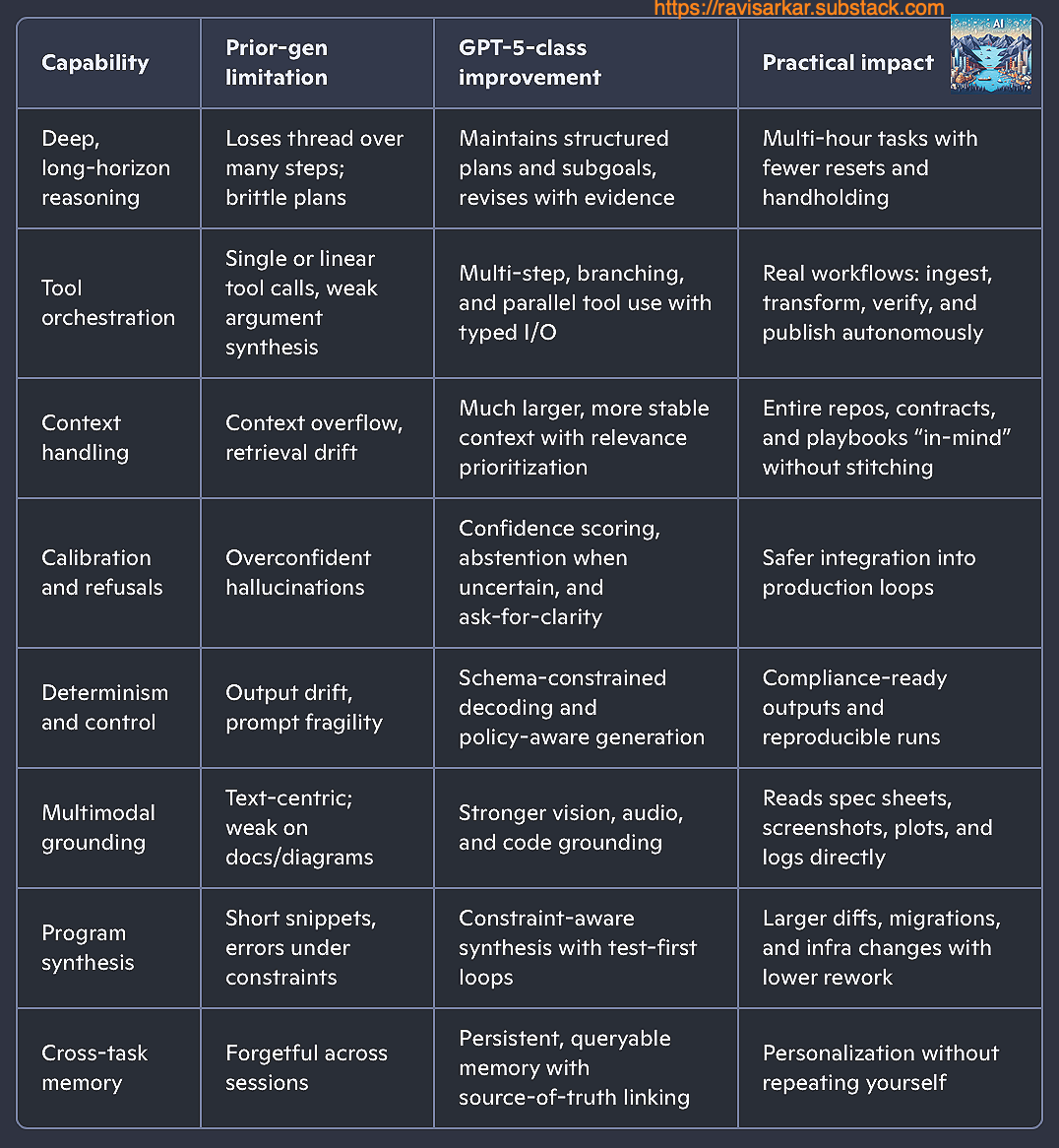
Unique, high‑impact use cases you can ship now
1) CFO Copilot for multi‑entity planning and hedging
Problem: Consolidations, currency swings, and covenant constraints create fragile plans.
Why prior models fell short: Can’t juggle multi‑currency ledgers, covenant logic, and scenario trees at once.
What GPT‑5‑class enables:
Connects to ERP/BI, reconciles ledgers, maps chart of accounts across entities.
Builds probabilistic forecasts (AR, seasonality, exogenous drivers) and scenario trees.
Suggests hedges and working capital moves subject to covenants and policies; drafts board memos.
Agent flow:
Data contracts: Validate schema of inputs, flag mismatches, request fixes.
Forecasts: Generate baseline + stress scenarios with confidence intervals.
Constraints: Encode covenants, tax, treasury policies.
Optimization: Select hedges, reorder capex, adjust hiring for risk‑adjusted targets.
Gov/Comms: Produce audit trail and exec summaries; schedule check‑ins.
KPIs:
Forecast calibration error (by segment)
Covenant breach probability over horizon
Cash conversion cycle delta
Hedge effectiveness vs policy limits
2) Contracting and supply chain negotiation with verifiable constraints
Problem: RFPs and MSAs are negotiated that do not map to operational limits.
Why prior models fell short: Missed edge cases, brittle term reconciliation, weak numeric reasoning.
What GPT‑5‑class enables:
Converts RFP/SoW/SLAs into machine‑checkable constraints and pricing models.
Simulates scenarios (volume ramps, penalties, lead times); proposes deal structures.
Drafts redlines and side letters with traceability to constraints.
Agent flow:
Constraint extraction: Terms → formal predicates (quantities, windows, penalties).
Simulation: Monte Carlo of demand/supply; evaluate service levels and costs.
Package: Redlines and negotiation arguments with quantitative backing.
KPIs:
Post‑signature dispute rate
Service level attainment variance
Negotiation cycle time
Margin vs risk index
3) Issue‑to‑merge engineering agent
Problem: Tickets stall between triage, reproduction, fix, tests, and rollout.
Why prior models fell short: Multi‑file reasoning breaks, flaky test synthesis, unsafe migrations.
What GPT‑5‑class enables:
Reads entire repos and CI logs; traces failure to root cause.
Proposes minimal diffs; writes tests first; runs locally; iterates on failures.
Produces migration plans, rollout checklists, and incident playbacks.
Agent flow:
Triage: Link issue to stack traces and commit history; create hypothesis tree.
Test‑first: Reproduce with failing tests; isolate flaky vs deterministic.
Patch: Constrained diffs; adhere to style and safety checks.
Validate: Run unit/integration/perf; analyze regressions.
PR: Title, description, risk analysis, and migration notes.
KPIs:
First‑pass merge rate
Test coverage delta per PR
Mean time to restore (from detection)
Regressions within 14 days
How GPT‑5‑class models supercharge reasoning agents
Design patterns that now work reliably
Plan‑act‑observe‑reflect loops
It maintains an explicit plan graph with subgoals, owners (tools/skills), and acceptance criteria.
Revises plans when observations contradict expectations; logs deltas for traceability.
Typed, multi‑step tool use
JSON‑schema constrained function calls with enums, unions, and nested objects.
Parallel calls when independent; join results with typed reducers.
Streaming partial arguments for long‑running tools; timeouts and retries with backoff.
Uncertainty‑aware control
Each assertion/output carries a confidence score and provenance (citations, tool results).
Gating: below threshold → ask for clarification or route to human.
Cross‑check with verifier prompts/models on high‑risk steps.
Memory architecture
Episodic: Per‑task state machine and artifacts.
Semantic: Vector + symbolic store of reusable facts and decisions with TTL and audit tags.
Policy: Guardrails and organizational constraints evaluated before output.
Multi‑agent orchestration
Specialists with clear contracts: Planner, Executor, Critic, Verifier, Reporter.
Debate or critique restricted to factual claims with evidence, not free‑form loops.
Budgeting: token/time budgets per subgoal; escalation paths.
Measuring reasoning quality (and preventing regressions)
Task success rate on multi‑step benchmarks representative of your workflows.
Tool‑call accuracy: valid schema rate, argument correctness, side‑effect success.
Plan completion rate: fraction of subgoals finished without human intervention.
Confidence calibration: expected vs observed accuracy by confidence bucket.
Consistency: answer stability across paraphrases and re‑asks.
Latency budget adherence: tail latency under parallel orchestration.
Safety/Compliance: policy violation rate under adversarial prompts.
Migration playbook: Upgrading from prior models
0–30 days
Inventory tasks → categorize by risk and value; pick 3–5 high‑leverage flows.
Wrap all tool calls with JSON Schema; add validators and mocks.
Add verification layers for high‑risk assertions.
Build evaluation harnesses with golden traces and live‑shadow runs.
31–60 days
Introduce explicit plan graphs and confidence scoring.
Add memory tiers (episodic, semantic, policy) with retention rules.
Roll out to low‑risk cohorts with human‑in‑the‑loop gating and drift monitoring.
61–90 days
Enable parallel tool graphs and budgeted multi‑agent roles.
Automate audit trails and executive reporting.
Expand to additional workflows; tighten thresholds as calibration improves.
Risks and countermeasures
Over‑automation risk: Gate with confidence thresholds and human review on high‑impact steps.
Retrieval contamination: Bind outputs to provenance; block claims without sources in regulated flows.
Prompt/format drift: Enforce schema/grammar decoding and contract tests for prompts.
Cost/latency creep: Parallelize independent steps; cache tool results; monitor tail latency.
The crux
You don’t adopt a new model to chase hype—you do it to move needles: cycle time, error rates, customer trust. GPT‑5‑class systems let you encode intent as plans, ground decisions in evidence, and close the loop without babysitting. It’s best to pick one painful workflow and make it unrecognizably better. The rest will probably follow.